还在为文献发愁?这篇干货告诉你“论文怎么搜索语言类”研究的正确打开方式

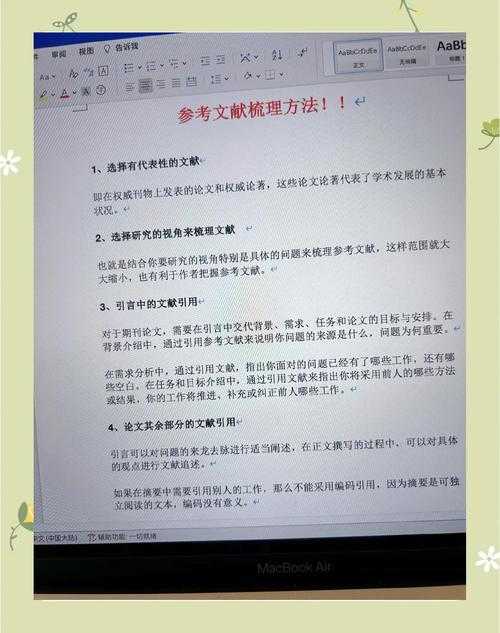
```html还在为文献发愁?这篇干货告诉你“论文怎么搜索语言类”研究的正确打开方式你好,我是Alex,一个在学术圈摸爬滚打了近十年的研究者。我清楚地记得,自己刚开始接...
还在为文献发愁?这篇干货告诉你“论文怎么搜索语言类”研究的正确打开方式
你好,我是Alex,一个在学术圈摸爬滚打了近十年的研究者。我清楚地记得,自己刚开始接触“论文怎么搜索语言类”这个课题时,那种茫然和无措——面对海量的数据库和复杂的检索式,感觉就像在大海捞针。如果你也正在为语言类论文的文献搜索而头疼,那么恭喜你,这篇文章就是为你准备的。今天,我们不谈空泛的理论,只分享最实用、最可复现的方法论,让你能立刻上手操作。
一、研究背景:为什么“论文怎么搜索语言类”如此重要?
在语言学、应用语言学、二语习得乃至计算语言学等领域,全面、精准的文献检索是研究的基石。一个失败的检索策略,可能导致你:

- 遗漏关键文献,使文献综述存在重大缺陷。
- 重复前人研究,浪费宝贵的科研时间和精力。
- 无法准确定位研究空白,导致研究问题缺乏创新性。
因此,掌握一套科学的“论文怎么搜索语言类”的方法,不仅仅是学会使用几个数据库,更是培养一种系统性、批判性的学术思维。
二、文献综述:前人是如何探索“论文怎么搜索语言类”的?
关于学术检索方法的研究已经相当成熟。我们发现,高效的语言类论文搜索策略通常遵循以下原则:
1. 多数据库协同检索
依赖单一数据库(如仅用CNKI或仅用Google Scholar)是新手常犯的错误。成熟的语言类论文搜索策略要求我们联动多个数据库:
- 综合性数据库:Web of Science, Scopus, Google Scholar(覆盖面广)。
- 语言学专业数据库:LLBA (Linguistics and Language Behavior Abstracts), MLA International Bibliography(内容精深)。
- 中文学术数据库:CNKI, 万方,维普(针对国内研究现状)。
2. 检索词的精准构建与扩展
这是语言类论文搜索策略的核心。例如,研究“任务型教学法对大学生英语口语流利度的影响”,你的检索词不应只有“任务型教学法”。一个完整的语言类论文搜索策略应包括:
- 核心概念:Task-based Language Teaching (TBLT), 任务型教学法。
- 研究对象:college students, university students, 大学生。
- 因变量:oral fluency, speaking fluency, 口语流利度。
- 同义词与近义词:如“fluency”可扩展为“automaticity”, “smoothness”。
三、研究问题与理论框架
基于以上综述,我们可以提出一个核心研究问题:如何构建一个高效、可复现的“论文怎么搜索语言类”的操作框架,以帮助研究者(尤其是新手)系统性地完成文献检索工作?
这个问题的理论框架可以借鉴信息检索领域的“检索模型”(如布尔模型、向量空间模型)和学术研究方法论中的“系统性综述”原则。简单来说,就是将模糊的搜索意图,转化为数据库能够精确理解的、结构化的检索指令。
四、研究方法与数据:手把手教你构建检索式
下面,我以一个具体案例,展示如何将上述框架落地。假设你的研究主题是:“基于语料库的汉语中介语发展研究”。
步骤一:分解研究主题,提取核心概念
- 概念A:语料库(Corpus, Corpus-based)
- 概念B:汉语中介语(Chinese Interlanguage, CIL)
- 概念C:发展(Development, Acquisition)
步骤二:为每个概念扩展关键词
| 核心概念 | 英文关键词 | 中文关键词 |
|---|---|---|
| 语料库 (A) | corpus, corpus-based, corpus linguistics | 语料库,基于语料库 |
| 汉语中介语 (B) | Chinese interlanguage, learner Chinese, L2 Chinese | 汉语中介语,留学生汉语,二语汉语 |
| 发展 (C) | development, acquisition, growth, longitudinal | 发展,习得,历时 |
步骤三:使用布尔运算符(AND, OR, NOT)构建检索式
在Web of Science等高级检索中,可以这样构建:
TS=( (corpus OR "corpus-based") AND ("Chinese interlanguage" OR "L2 Chinese") AND (development OR acquisition OR longitudinal) )
小技巧:使用引号“”来锁定短语,如“Chinese interlanguage”,避免数据库拆解单词。使用星号*进行词干检索,如develop* 可以匹配 develop, development, developing。
五、结果与讨论:如何筛选与管理文献?
执行检索后,你可能会得到数百甚至上千条结果。此时,一个清晰的筛选流程至关重要:
- 初步筛选(通过标题和摘要):快速排除明显不相关的文献。重点关注研究方法、研究对象和核心发现是否与你的研究匹配。
- 精细阅读(全文阅读):对初步筛选出的文献进行精读,并开始做阅读笔记。我强烈建议使用Zotero或Mendeley等文献管理工具,它们可以帮你自动生成参考文献,并方便地做笔记和分类。
- 雪球法(追溯参考文献):从一篇高质量文献的参考文献列表中,往往能发现更多宝藏文献,这是对数据库检索的极佳补充。
六、结论与启示
总结来说,解决“论文怎么搜索语言类”的难题,关键在于从“搜索”转变为“检索”。“搜索”是随意的、尝试性的,而“检索”是系统的、有策略的。它要求你:
- 明确研究边界,精准定义概念。
- 掌握布尔逻辑,构建高效检索式。
- 熟练运用专业数据库,并懂得利用“雪球法”查漏补缺。
- 借助文献管理工具,实现知识的有序管理。
七、局限与未来研究
本文提供的框架主要针对实证类研究文献的检索。对于理论性、哲学性较强的语言学流派研究,其检索策略可能更侧重于经典专著和特定学派的核心期刊,检索式的构建方式会有所不同。此外,随着人工智能技术的发展,未来可能会出现更智能的语义检索工具,能够更好地理解研究者的自然语言提问,但这并不意味着策略性思考的过时,反而对我们提出更高层次的概念化能力要求。
你的下一步行动建议
现在,请不要再只是阅读。我建议你:
- 立刻打开一个文档,写下你当前的研究课题。
- 按照本文的步骤,尝试分解出2-3个核心概念,并为每个概念扩展5-10个中英文关键词。
- 选择Web of Science或Scopus中的一个,亲手构建你的第一个专业检索式。
实践是唯一的捷径。如果在操作中遇到任何问题,欢迎随时交流。祝你文献检索顺利,科研之路坦荡!
—— 你的朋友,Alex
```更多关于- 还在为文献发愁?这篇干货告诉你“论文怎么搜索语言类”研究的正确打开方式 - 请注明出处
发表评论