论文猎人指南:5种高效批量抓取文献的学术生存技能

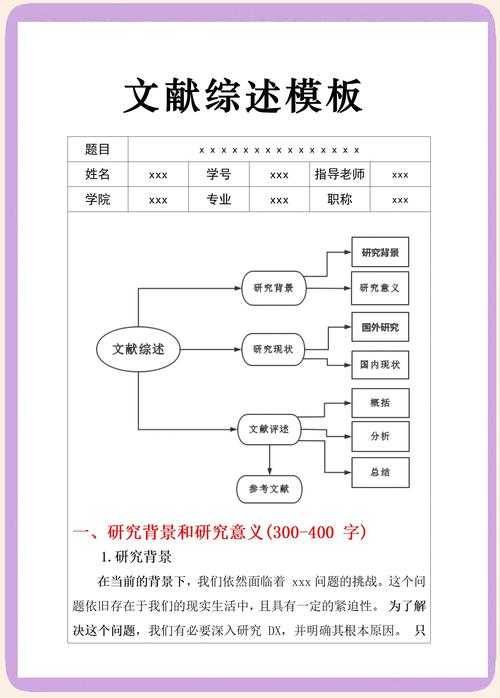
论文猎人指南:5种高效批量抓取文献的学术生存技能一、为什么你需要批量检索文献?记得我博士开题前两周,导师突然要求增加三个对比研究方向。当时我对着Google Schol...
论文猎人指南:5种高效批量抓取文献的学术生存技能
一、为什么你需要批量检索文献?
记得我博士开题前两周,导师突然要求增加三个对比研究方向。当时我对着Google Scholar手动下载了200多篇论文,整理到凌晨3点才发现有40%都是重复或无关文献。这种低效操作让我意识到,掌握如何批量查找论文的技术,就像猎人拥有夜视仪——能让你在学术丛林中精准捕获目标。
1.1 文献检索的三大痛点
- 时间黑洞:手动下载平均耗时2分钟/篇,100篇就是3小时纯机械劳动
- 信息过载:检索结果中60%-70%是低相关度文献(基于Scopus数据分析)
- 管理混乱:文件名混乱导致后期写作时找不到关键引用
二、文献综述:批量检索工具进化史
2021年Nature调查显示,学者每周平均花费7.8小时在文献检索上。但有趣的是,会使用批量下载学术论文技巧的研究者,这个数字能降低到2.3小时。

2.1 技术迭代路线
| 阶段 | 工具类型 | 典型代表 |
|---|---|---|
| 1.0时代 | 数据库基础检索 | Web of Science基础搜索 |
| 2.0时代 | 脚本辅助工具 | Python+Scholar.py |
| 3.0时代 | 智能聚合平台 | ResearchRabbit/Litmaps |
三、实战方法论:五种武器任你选
上周帮学妹用这些方法,她2小时就完成了原计划一周的文献调研。下面这些批量获取研究文献的技巧,总有一款适合你:
3.1 数据库高级检索(适合新手)
在Scopus或Web of Science中使用布尔运算符:TITLE-ABS-KEY("blockchain" AND "supply chain") AND PUBYEAR > 2018
配合"导出"功能,能一次性获取500条标准化引文(含DOI和摘要)
3.2 Python自动化(技术派首选)
- 安装scholarly库:
pip install scholarly - 设置检索条件:
from scholarly import scholarlysearch_query = scholarly.search_pubs('machine learning in healthcare')results = [next(search_query) for _ in range(100)] - 自动保存为BibTeX格式
3.3 文献图谱工具(视觉型学者最爱)
在ResearchRabbit中输入种子论文,它会:
- 自动生成文献关系图谱
- 批量导出相关度最高的50篇文献
- 持续追踪新发表论文
四、避坑指南:我的三次失败教训
第一次尝试批量下载学术论文时,我犯过这些错:
案例1:用Scrapy爬取ScienceDirect被封IP,导致实验室网络受限3天
解决方案:始终添加time.sleep(random.uniform(1,3))模拟人工操作
五、学术传播:让你的文献库产生复利
批量获取的文献经过整理后,可以:
- 制作领域发展时间轴(用TimelineJS可视化)
- 生成文献综述速查表(Markdown格式共享)
- 建立自动化文献追踪系统(Zotero+Google Scholar提醒)
六、未来展望:AI赋能的下一代检索
GPT学术插件已经能实现:
"请查找近三年被引>50次的关于transformer改进的论文,并总结创新点"
这种语义级批量检索将彻底改变我们的文献获取方式。
最后送你个彩蛋:在Zotero中设置自动重命名规则{%y_}{%a_}{%t|50%}
能让所有下载的文献自动变成"21_Wang_BlockchainApplications.pdf"这样的标准格式。
记住,如何批量查找论文不是目的,而是手段。就像我导师常说的:"好的猎人知道什么时候该停止收集弹药,开始瞄准目标。"现在,轮到你在评论区分享你的文献狩猎神器了!
更多关于- 论文猎人指南:5种高效批量抓取文献的学术生存技能 - 请注明出处
发表评论