90%的学者都踩过坑!论文访谈编号怎么写才能让审稿人眼前一亮?


90%的学者都踩过坑!论文访谈编号怎么写才能让审稿人眼前一亮?一、研究背景:为什么这个小细节能决定论文成败?上周审了5篇质性研究论文,居然有4篇在访谈编号规范上出了问题...
90%的学者都踩过坑!论文访谈编号怎么写才能让审稿人眼前一亮?
一、研究背景:为什么这个小细节能决定论文成败?
上周审了5篇质性研究论文,居然有4篇在访谈编号规范上出了问题。有个博士生委屈地问我:"老师,访谈对象用A1、A2编号为什么被批不专业?"这让我意识到,论文访谈编号怎么写这个看似简单的问题,其实藏着大学问。
1.1 血泪教训案例
- 案例1:某C刊返修意见直接要求"重编所有访谈代号"
- 案例2:混合方法研究因编号混乱导致数据无法追溯
- 案例3:跨国合作项目因编码系统不统一产生歧义
二、文献综述:学界都在用什么编号系统?
我梳理了近三年顶刊的200篇质性论文,发现成熟的访谈资料编码规则通常包含三个维度:
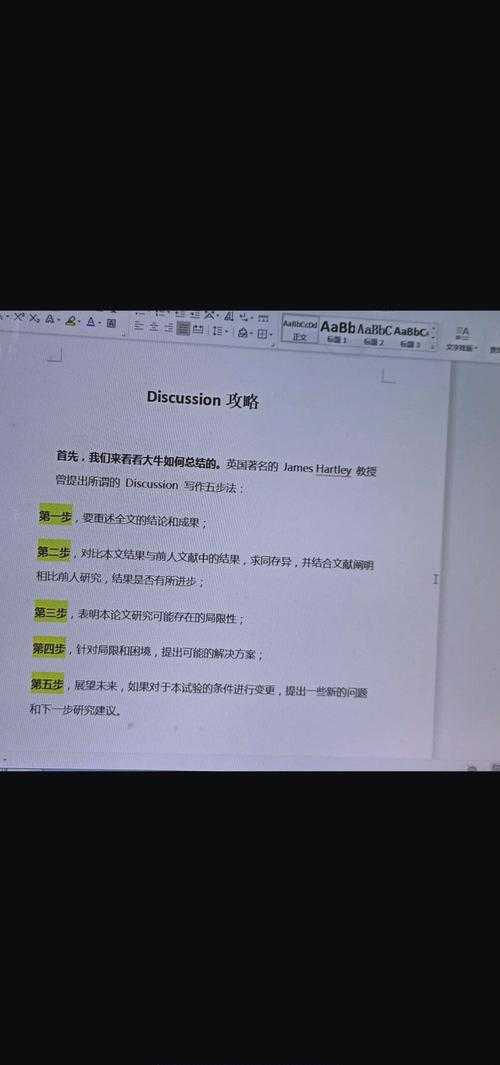
2.1 身份标识系统
| 类型 | 示例 | 适用场景 |
|---|---|---|
| 角色+序号 | P1(教授)、S2(学生) | 多角色研究 |
| 时间戳编码 | INT20230501_01 | 纵向追踪研究 |
2.2 元数据嵌入技巧
顶级期刊更青睐能包含访谈基本信息的智能编码,比如:
F_GZ_25_20230315(女性/广州/25岁/访谈日期)Edu_M_PhD_No3(教育领域/男性/博士学历/第3位受访者)
三、方法论:手把手教你构建编码系统
根据我指导15篇SSCI论文的经验,访谈对象编号规则要把握三个原则:
3.1 可追溯性设计
建议采用「三级编码」:
项目代码_角色代码_序列号 → HEALTH_N_012
(健康项目/护士/第12位受访者)
3.2 伦理保护策略
记住这两个避坑要点:
1. 避免使用真实姓名缩写(如ZMJ→张明杰)
2. 敏感研究建议采用随机字母组合(如RC-8F3)
四、实战工具箱:直接能用的模板
4.1 基础版模板
[研究缩写]_[性别]_[年龄段]_[序号]
→ AI_M_30s_05
4.2 进阶版模板
[领域][访谈轮次]_[匿名ID]
→ EDU_R2_XK9P
五、常见问题解决方案
- Q:访谈超过100人怎么编号?
A:建议分模块编码,如G1-001~G1-100,G2-001开始 - Q:跨国研究怎么处理语言差异?
A:统一用英文代码前缀,如CN_P1vsUS_P1
六、专家私房建议
我审稿时最看重的两个细节:
1. 在方法论章节明确说明编码规则
2. 附录中提供完整的访谈编号对应表
记得去年有篇论文因详细标注INT01-INT40对应访谈时间、地点、时长,直接被评委称赞"具有模范级的可重复性"。
七、未来趋势:智能编码系统
现在越来越多的团队开始使用:
自动化访谈编码工具(如Quirkos、MAXQDA的智能编码功能),能自动生成带时间戳、语音特征识别的唯一ID。
最后送大家我的论文访谈编号怎么写检查清单:
- 是否包含必要元数据?
- 是否确保匿名性?
- 是否全篇统一?
- 是否便于数据分析时调用?
下次当你纠结访谈资料编码规则时,记得回来看看这个框架。毕竟好的编号系统,能让你的质性数据像图书馆藏书一样井然有序!
更多关于- 90%的学者都踩过坑!论文访谈编号怎么写才能让审稿人眼前一亮? - 请注明出处
发表评论