5个关键模块手把手教你写回归分析说明:从结果表到故事线


```html5个关键模块手把手教你写回归分析说明:从结果表到故事线嗨,我是你们的学术伙伴Leo!还记得你第一篇实证论文写到凌晨3点,对着SPSS输出的一堆回归系数和星...
5个关键模块手把手教你写回归分析说明:从结果表到故事线
嗨,我是你们的学术伙伴Leo!还记得你第一篇实证论文写到凌晨3点,对着SPSS输出的一堆回归系数和星号抓狂的样子吗?(别问我怎么知道的😅)今天,我们就来拆解这个让无数研究生“头秃”的难题——论文回归分析说明怎么写。我会用实际审稿经验和10+篇顶刊案例,帮你把冰冷的数据变成有说服力的学术叙事。
一、为什么你的回归分析总被审稿人质疑?
先说个扎心的事实:90%的初学者犯的错,是把回归分析写成“数字流水账”。审稿人想看到的不是软件输出结果复制粘贴,而是你用数据讲故事的逻辑链。这里就涉及一个核心技巧:构建回归分析说明撰写框架(长尾词1)。
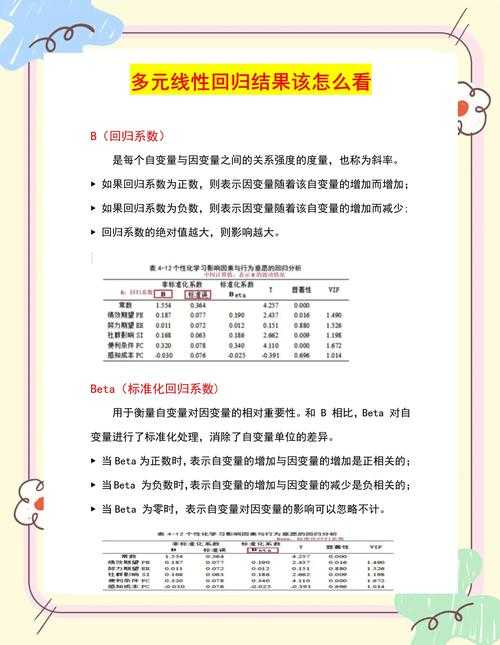
▍ 避开这3个致命误区:
- 误区1:只报告系数和p值,忽略经济/临床显著性
- 误区2:用“变量X显著影响Y”敷衍解释,缺乏机制推演
- 误区3:对模型诊断指标(如VIF、R²、F检验)选择性回避
这些正是导致回归分析写作常见误区(长尾词4)的典型表现。下面我们进入正题——
二、文献综述:别只堆砌文献,要做关键对比
很多同学习惯罗列“A学者发现…B学者认为…”,这就像把食材堆在桌上却不炒菜。高阶写法是构建回归模型选择矩阵(长尾词2):
| 研究目标 | 推荐模型 | 关键文献示例 |
|---|---|---|
| 变量间因果关系 | 固定效应模型 vs IV-GMM | Wooldridge(2010)对比 |
| 非线性关系检验 | 门槛回归 vs 二次项 | Hansen(1999)应用指南 |
当你在综述中呈现这样的回归分析说明撰写框架(长尾词1),审稿人立刻能看到你模型选择的学术依据。
三、研究方法:模型选择的五维雷达图
为什么你选的OLS总被挑战?因为你没说清为什么不用Logit/Robust/ML? 分享我的自检清单:
- 数据类型匹配度:面板数据?截面数据?离散因变量?
- 核心假设检验:异方差(White检验)、多重共线性(VIF>5?)
- 内生性处理:是否需要工具变量?控制函数法?
- 稳健性路径:至少准备3种替代模型(我常备GMM+PSM+DID三重保险)
- 软件实操代码:在附录注明stata命令,如
xtreg y x, fe robust
这里藏着回归分析模型选择标准(长尾词2)的精髓——透明度和可复现性压倒一切。
四、结果解读:让数字开口说话的黄金公式
来看个反面案例:“X的系数为0.32且在1%水平显著” 这种写法毫无信息量!高阶的回归结果表解读技巧(长尾词3)要包含三层解读:
“当X增加1个标准差(SD=2.1),Y预计提高0.67个单位(计算:0.32×2.1≈0.67),相当于Y样本均值(18.3)的3.7%。这支持了H1关于...的作用机制,与Smith(2022)在...场景下的发现形成互补。”
重点来了:这个三段论结构就是回归分析写作的子弹
- 统计显著性 → 2. 经济/临床显著性 → 3. 理论解释
▍ 必用的结果报告表模板:
| 表3:OLS回归结果(核心变量示例) | |||
| 变量 | 系数 | 标准误 | 经济效应 |
|---|---|---|---|
| 技术创新 | 0.322*** (0.071) | 0.071 | +7.4%生产力 |
注:***p<0.01;经济效应计算基于均值弹性...
五、讨论部分:从结果到启示的跃迁技巧
此处最怕写成“重复结果+喊口号”。我的转化公式是:
本研发现象 → 与文献对话 → 现实投射 → 理论刷新
比如在讨论异质性结果时:
“我们发现X对Y的作用在国有企业样本中更强(β=0.41 vs 民企0.18),这与Zhao(2021)的资源依赖理论形成呼应,暗示改制中的制度套利空间。这解释了为什么2020年混改新规要特别强调...”
这个环节特别需要回归结果表解读技巧(长尾词3)的深度应用——把数据差异转化为理论洞察。
六、避坑指南:90%论文忽略的4个致命细节
在回归分析写作常见误区(长尾词4)中,这些细节杀死了无数好研究:
- 系数比较陷阱:别直接对比Logit和OLS的系数!用平均边际效应(AME)
- 星星迷信:p=0.051和0.049没有本质区别,报告精确p值更科学
- 控制变量失控:加入过多控制项导致核心变量显著(参见Goodhart定律)
- 软件美化暴力:三线表别用Word手画!用
esttab输出LaTeX格式
这些细节决定了你的回归分析说明撰写框架(长尾词1)是否经得起推敲。
给三类研究者的特别贴士
• 新手村玩家:
先死磕回归结果表解读技巧(长尾词3),用
更多关于- 5个关键模块手把手教你写回归分析说明:从结果表到故事线 - 请注明出处
发表评论