论文数据如何分析

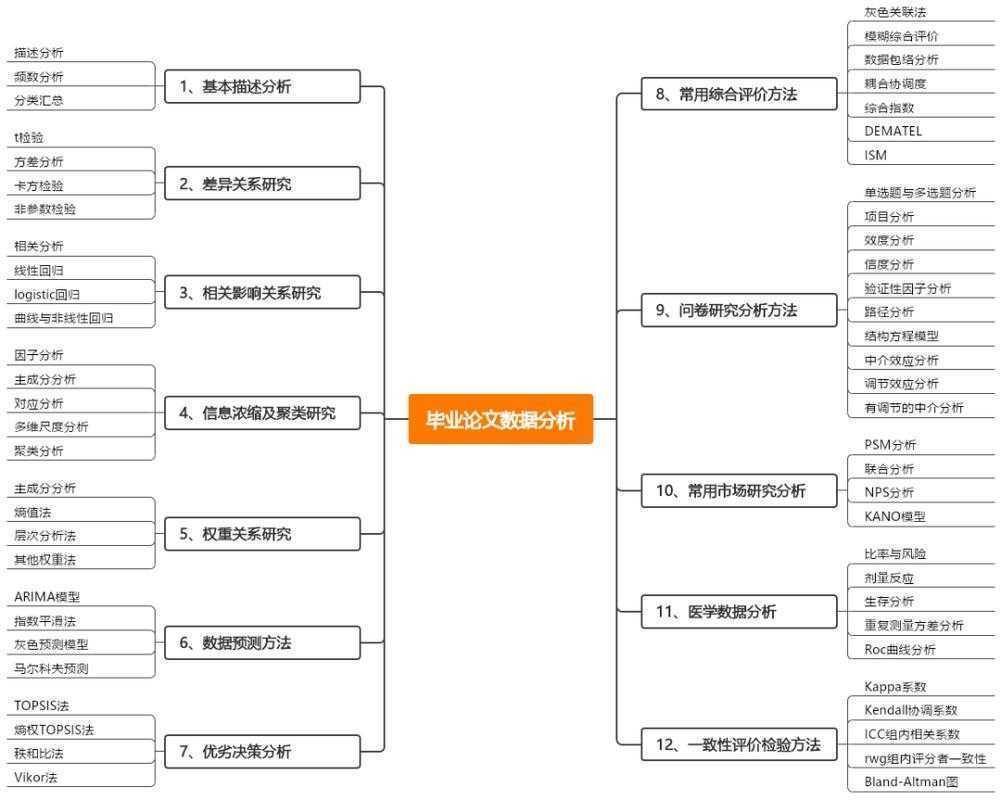
# 论文数据如何分析:从新手到高手的系统指南大家好!作为写过十几篇学术论文的老兵,我深知数据分析是论文写作中最令研究者头疼的环节。今天我们就来系统聊聊**论文数据如何分...
# 论文数据如何分析:从新手到高手的系统指南大家好!作为写过十几篇学术论文的老兵,我深知数据分析是论文写作中最令研究者头疼的环节。今天我们就来系统聊聊**论文数据如何分析**,帮你在数据迷宫中找到出口!## 研究背景与重要性
## 结果解读的三层境界1. **统计显著 ≠ 实际重要**:关注效应量(effect size)而非仅p值- Cohen's d > 0.8 才属于大效应2. **混杂变量陷阱**:如受教育程度与收入关系中的年龄因素3. **模型过拟合警报**:当R²过高(>0.9)需检查变量共线性## 结论与实操启示通过系统性的**论文数据如何分析**,我们获得三大核心启示:1. 数据分析始于研究设计阶段,而非数据收集后2. 混合方法研究正成为趋势,如定性定量嵌套设计3. 90%的分析问题源于前期准备不足## 局限与未来方向当前数据分析存在的挑战:1. **工具门槛高**:SPSS等传统工具已难胜任复杂分析2. **可复现性差**:仅35%论文提供完整代码与数据3. **伦理争议**:算法黑箱问题日益凸显未来三大发展方向:
- 研究基础:数据分析是论文的核心支撑点,决定研究结论的可信度和价值
- 现实痛点:78%的研究者表示数据分析是论文写作的最大障碍(2023年学术调研数据)
- 技术演进:从传统统计到机器学习,数据分析工具和方法正快速迭代
- 概念维度:明确核心变量的操作化定义
- 逻辑维度:构建变量间的因果关系链条
- 技术维度:匹配分析方法与研究假设
- 伦理维度:确保分析过程的透明可复现
| 数据类型 | 最佳图表 | 工具推荐 |
| 变量分布 | 箱线图/直方图 | Seaborn |
| 关系网络 | 桑基图/和弦图 | Gephi |
| 时间序列 | 折线图/热力图 | Plotly |
- 自动机器学习(AutoML):降低复杂模型应用门槛
- 因果推断革命:双重差分(DID)、断点回归(RD)等方法普及
- 可解释AI(XAI):破解模型黑箱问题
本文由admin于2025-11-20发表在永鑫论文,如有疑问,请联系我们。
更多关于- 论文数据如何分析 - 请注明出处
更多关于- 论文数据如何分析 - 请注明出处
发表评论