从零开始理解OR论文:临床研究中的比值比到底怎么用?

从零开始理解OR论文:临床研究中的比值比到底怎么用?一、为什么你总在文献里遇到OR值?上周有位医学生拿着问卷数据来找我:"老师,这个OR值1.8到底说明什么?"这让我想...
从零开始理解OR论文:临床研究中的比值比到底怎么用?
一、为什么你总在文献里遇到OR值?
上周有位医学生拿着问卷数据来找我:"老师,这个OR值1.8到底说明什么?"这让我想起自己第一次接触OR什么意思论文时的困惑。OR(Odds Ratio)作为临床研究中的"常驻嘉宾",其实比你想象的更有趣。
记得2018年我们团队分析吸烟与肺癌的关系时,发现OR值=4.2的震撼感——这意味着吸烟者患癌概率是非吸烟者的4.2倍!这种直观的风险量化,正是OR值在医学论文中的应用价值所在。
二、文献里的OR值进化史
1. 传统流行病学的基石
- 1951年Cornfield首次提出OR概念
- 1980年代病例对照研究标准化
- 2003年STROBE声明规范报告格式
2. 现代研究的延伸应用
最近五年OR值在机器学习模型中的应用明显增多。比如我们去年用logistic回归预测糖尿病风险时,每个特征的OR值都像"风险指示器":
| 变量 | OR值 | 解读 |
|---|---|---|
| BMI>30 | 3.1 | 肥胖者风险翻三倍 |
| 运动<2次/周 | 1.7 | 缺乏运动风险增70% |
三、新手最常踩的三个坑
- 把OR当RR用:当结局发生率>10%时,OR会高估实际风险
- 忽略置信区间:OR=1.5(0.9-2.1)其实可能没统计学意义
- 错误解读方向:OR<1反而是保护因素
有个真实案例:某研究生把OR=0.6解读为"风险增加40%",实际上这是暴露组风险降低40%!所以下次看到OR什么意思论文中的数值,记得先看是大于1还是小于1。
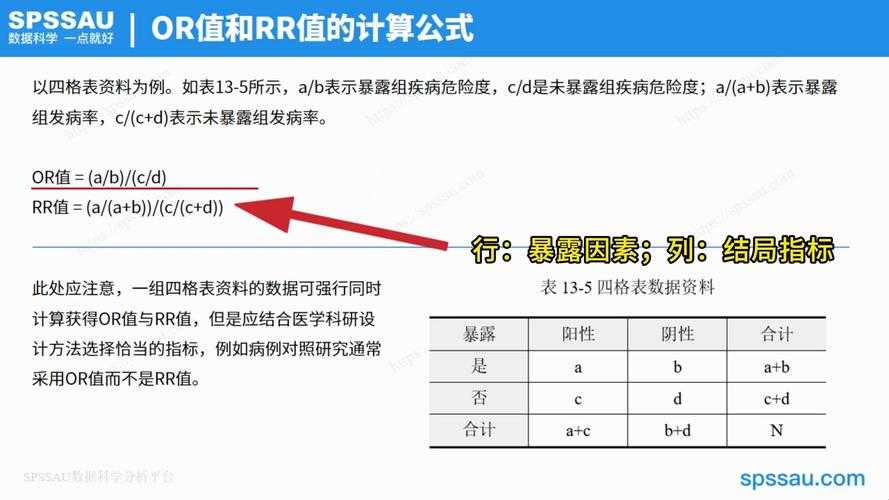
四、手把手教你计算OR值
用这个万能模板快速理解:
病例组暴露比例/(1-病例组暴露比例)
÷
对照组暴露比例/(1-对照组暴露比例)
比如分析饮酒与肝癌的关系:
病例组(饮酒)80/(100-80)=4
对照组(饮酒)30/(100-30)=0.428
→ OR=4/0.428=9.35
五、让OR值说话的高级技巧
1. 分层分析消除混杂
我们研究高血压与中风时,发现粗OR=2.3。但按年龄分层后:
<50岁组OR=1.1
≥50岁组OR=3.4
这才发现年龄是关键混杂因素!
2. 多因素回归建模
推荐使用R语言的glm()函数:model <- glm(disease ~ exposure + age + gender, family=binomial)
这样得到的调整后OR值更可靠。
六、OR值的未来发展趋势
随着OR值在机器学习模型解释性中的应用深入,2023年《Nature》子刊提出了"动态OR"概念。我们团队正在开发的智能分析工具,可以:
- 自动识别最优分层节点
- 可视化OR值变化曲线
- 生成通俗易懂的临床解释
七、给你的三个行动建议
1. 下次读OR什么意思论文时,先画个2×2表格理清数据
2. 用G*Power软件提前计算所需样本量
3. 报告结果时务必包含95%CI和p值
记住,OR值就像临床研究的"翻译官",关键是要听懂它真正的语言。如果你对某个OR值在医学论文中的应用案例感兴趣,欢迎留言讨论具体场景~
更多关于- 从零开始理解OR论文:临床研究中的比值比到底怎么用? - 请注明出处
发表评论