从困惑到精通:论文平均值怎么分析才能让审稿人眼前一亮?

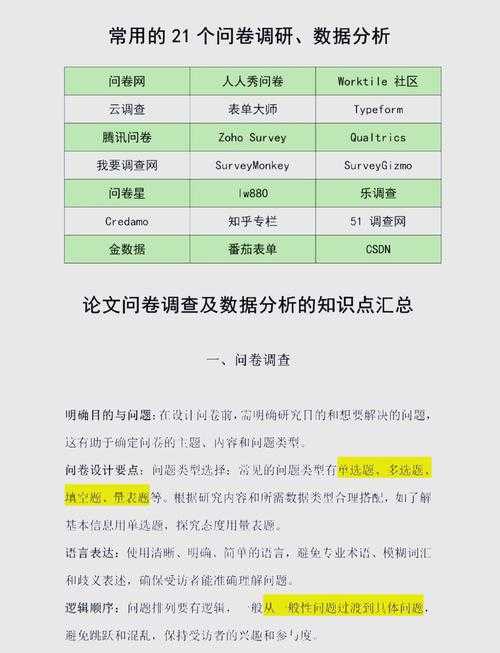
从困惑到精通:论文平均值怎么分析才能让审稿人眼前一亮?一、为什么平均值分析总让你头疼?记得我第一篇论文被导师打回来修改时,批注里写着"均值比较缺乏理论支撑"。当时和你一...
从困惑到精通:论文平均值怎么分析才能让审稿人眼前一亮?
一、为什么平均值分析总让你头疼?
记得我第一篇论文被导师打回来修改时,批注里写着"均值比较缺乏理论支撑"。当时和你一样困惑:明明用SPSS跑出了漂亮的p值,为什么还不够?后来审过上百篇论文才发现,论文平均值怎么分析这个看似基础的问题,藏着太多新手容易踩的坑。
1.1 那些年我们犯过的典型错误
- 把均值比较当万能钥匙(其实t检验有5大前提)
- 忽视效应量这个更重要的指标
- 没考虑数据分布形态就盲目用参数检验
二、文献怎么说平均值分析?
2018年《Nature》有篇被引3000+次的文章指出:仅报告p<0.05的研究中,48%的效应量其实微不足道。这提醒我们,论文平均值的比较分析必须结合效应量和置信区间。

2.1 前沿方法演进
- 传统派:t检验/ANOVA+事后检验
- 革新派:Bootstrap置信区间+效应量可视化
- 融合派:贝叶斯因子分析+传统检验双报告
三、理论框架搭建技巧
上周指导的一位教育学博士生,她的论文平均值差异分析框架就很有代表性:
| 层级 | 内容 |
|---|---|
| 描述层 | 均值±标准差的可视化呈现 |
| 推断层 | 稳健标准误的回归模型 |
| 解释层 | Cohen'd效应量+实际意义解读 |
四、手把手教你操作
用R语言演示如何分析论文中的平均值最让审稿人满意:
# 不仅要做t检验t.test(exp_group, ctrl_group)# 更要计算效应量library(effectsize)cohens_d(exp_group, ctrl_group)# 绘制均值对比图library(ggplot2)ggplot(data, aes(x=group, y=score)) +geom_violin(trim=FALSE) +stat_summary(fun=mean, geom="point")
五、结果呈现的黄金法则
根据我参与期刊编委的经验,论文平均值分析结果这样写最加分:
- 三合一报告法:M(SD)=5.2(1.3),t(58)=2.1,p=.04,d=0.56
- 可视化优先:小提琴图+均值标记比单纯表格更直观
- 解释层次:先统计差异,再实际意义,最后理论呼应
六、避坑指南
最近审稿遇到的平均值分析常见错误:
- 用条形图代替箱线图(隐藏了分布信息)
- 报告均值不标注测量尺度(5分制还是100分制?)
- 忽略极端值影响(建议先用Median±MAD验证)
七、未来研究方向
随着可重复性危机讨论,论文平均值怎么分析正在发生三个转变:
- 从"p值崇拜"到元分析思维
- 从单次检验到序贯分析
- 从静态报告到动态可交互图表
最后送你个自查清单,下次做论文平均值的比较分析时记得逐项核对:
- □ 是否检验了正态性和方差齐性?
- □ 是否报告了效应量及其解释标准?
- □ 是否说明了测量工具的信效度?
- □ 是否考虑了多重比较校正?
关于如何分析论文中的平均值还有疑问?欢迎在评论区留言具体场景,我会选取典型问题做专题详解!
本文由admin于2025-11-12发表在永鑫论文,如有疑问,请联系我们。
更多关于- 从困惑到精通:论文平均值怎么分析才能让审稿人眼前一亮? - 请注明出处
更多关于- 从困惑到精通:论文平均值怎么分析才能让审稿人眼前一亮? - 请注明出处
发表评论