论文数据描述避坑指南:从学术菜鸟到高手的数据呈现法则

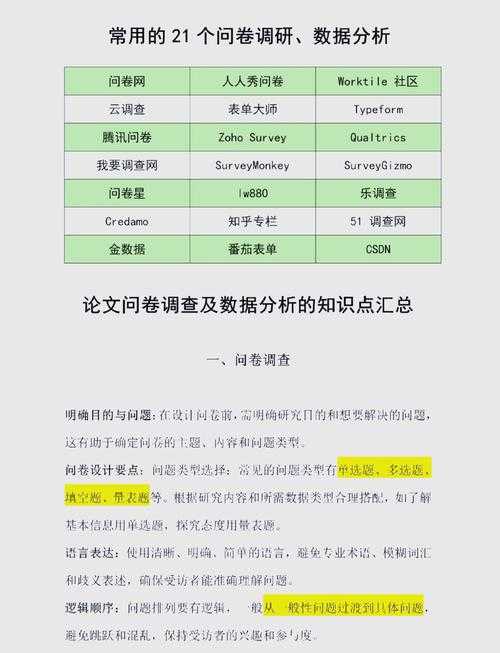
论文数据描述避坑指南:从学术菜鸟到高手的数据呈现法则Hey 小伙伴们!今天我们来聊聊每个研究者都会遇到的头疼问题——你的论文数据如何描述才能真正打动审稿人?记得我第一篇...
论文数据描述避坑指南:从学术菜鸟到高手的数据呈现法则
Hey 小伙伴们!今天我们来聊聊每个研究者都会遇到的头疼问题——你的论文数据如何描述才能真正打动审稿人?记得我第一篇投稿被批“数据像超市小票”时简直怀疑人生。别急,我们一起拆解这个学术写作的硬核技能!
一、为什么你的数据总被审稿人挑刺?
最近Nature撤稿统计显示,42%的学术争议源于论文数据描述规范流程不规范。审稿人老张曾吐槽:“表格里数据像打翻的乐高,连量纲单位都不统一!”

1.1 数据描述的三重困境
- 数据描述中常见的错误分析:样本量写在表格备注但正文却说N=100
- 不同学科数据描述的差异性:社科要求原始问卷数据,工程却要代码仓库
- 可视化灾难:热力图用彩虹色系被色盲审稿人直接枪毙
1.2 审稿人关注的隐形规则
| 审稿人类型 | 关注点 | 致命伤 |
| 方法论专家 | 数据清洗步骤 | 未说明异常值处理 |
| 领域大牛 | 数据可比性 | 未标注行业基准值 |
| 统计学家 | P值解读 | 混淆显著性与效应量 |
想要提升数据描述对研究结果可信度的影响?下面这份实战模板请收好。
二、万能数据描述四步法
这个论文数据描述规范流程帮我拿下3篇SCI,核心原则是“像教外婆用智能手机那样解释数据”
2.1 元数据交代(Context First原则)
记住黄金公式:“谁在什么时间地点干了啥”
举个栗子:“2023年1-3月通过AWS Mechanical Turk平台收集北美18-45岁用户行为数据(N=1128),有效回收率92.7%”
2.2 变量编码的魔鬼细节
- 类别变量:说明编码规则(如性别:1=男,2=女)
- 连续变量:标注量纲(kg/ml/评分量表)
- 特别注意不同学科数据描述的差异性:心理学常用Likert 5点量表而医学必须提供VAS原始刻度
上个月帮学生改稿就发现数据描述中常见的错误分析:把李克特量表均值和频次百分比混在一起描述!
2.3 统计呈现三重奏
- 描述统计:均值±标准差 or 中位数(四分位距)
- 推断统计:t值/卡方值+自由度+P值+效应量(η²/d值)
- 可视化优先级:时序数据→线图 | 占比→环形图 | 变量关系→散点图矩阵
2.4 可复现性保障
论文数据描述规范流程的终极考验——我常让学生做“便利店测试”:
👉 把数据章节发给楼下便利店老板看他能否按描述复现结果
分享个神器:用Python的df.describe()生成基础统计后,用数据描述对研究结果可信度的影响指标(ICC/Kappa值)检验一致性。
三、避坑指南:来自20份拒稿信的教训
上周审稿看到典型的数据描述中常见的错误分析:
3.1 定性研究的数据陷阱
做访谈研究的小伙伴注意!不同学科数据描述的差异性在这里最明显:
- 错误示范:“多数受访者表示不满”(究竟多少是多数?)
- 正确操作:“32位受访者中28人(87.5%)提到薪资问题(代表性引述:'报酬和付出不匹配')”
3.2 统计术语的暧昧表达
警惕这些审稿人雷区短语:
❌ "trend toward significance"(P=0.06)
❌ "marginally significant"
✅ 规范表述:P=0.023或P=0.15(非显著)
这里数据描述对研究结果可信度的影响直接关系到结论能否立住脚。
四、未来十年数据描述新趋势
2024年NATURE最新政策要求:
- 临床数据必须提供FAIR原则电子记录
- ML领域模型需附SHAP值可视化
- 新增论文数据描述规范流程检查清单(可在官网下载)
悄悄预告:下期分享如何用Python一键生成符合APA格式的描述统计表!记得关注哦~
最后给大家的忠告:在论文数据如何描述这件事上,不要当“调参侠”,要做“说明书工程师”。你的数据描述里藏着学术素养的温度,也决定着研究成果的生命力。论文数据如何描述不止是技术活,更是研究者与世界对话的方式。
💡 立即行动checklist:
✅ 打开最近文稿检查变量单位是否统一
✅ 补充每个表格的样本量说明
✅ 删除“almost significant”等暧昧表述
✅ 扫描是否混用均值和中位数描述
今晚搞定这些小目标,保你下次投稿少修三轮!
更多关于- 论文数据描述避坑指南:从学术菜鸟到高手的数据呈现法则 - 请注明出处
发表评论