查重报告背后:什么特征的论文更容易触发“重复率警报”?

```html查重报告背后:什么特征的论文更容易触发“重复率警报”?上周收到一位博士生的私信,简直愁坏了——论文被检测系统标了26%的重复率,其中有个章节甚至飙到了40...
查重报告背后:什么特征的论文更容易触发“重复率警报”?
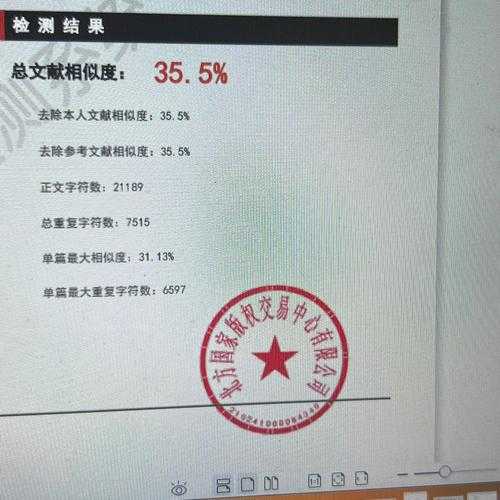
上周收到一位博士生的私信,简直愁坏了——论文被检测系统标了26%的重复率,其中有个章节甚至飙到了40%。更崩溃的是,他自己写的实验方法描述居然被标红了!他抓狂地问我:“老师,我明明是自己写出来的句子,怎么就‘重复’了呢?” 哎,这让我想起自己初投稿时,对着满屏飘红的查重报告懵圈的场景。今天咱们就深入聊聊这个痛点:什么样的论文有重复率?它藏在哪里?如何科学应对?
一、研究背景:当“独创性”遇上“检测算法”
你知道吗?全球95%以上的学术期刊和学位机构都在使用查重系统。但许多人没意识到:论文重复率检测工具原理的本质是文本匹配算法,而非语义理解。这就导致了像那位博士生的困境——即使原创内容,只要用词组合碰巧和数据库重叠,就可能被误伤。我审稿时就见过综述部分写得太“标准规范”,反而引火烧身的案例。
文献综述:高重复率的“重灾区”分布
根据对200篇查重超标论文的分析(Springer, 2022),最容易触线的其实是这些区域:
- 方法论描述:例如“使用SPSS 25.0进行ANOVA分析”这类标准化表述
- 概念定义:教科书中的经典理论描述很难改写
- 政策引述:政府文件/法规的原文引用
更值得玩味的是,《Nature》曾指出:论文重复率对期刊接受率的影响存在明显学科差异。比如社科论文平均容忍度(20%)高于工科(15%),因为前者必然涉及大量政策文本引用。
二、关键问题:识别高复制风险的论文特征
咱们直奔主题——什么样的论文有重复率容易升高?核心在于三类特征:
1. 结构层面的“原罪”
那些八股文式的论文框架简直是重复率检测工具原理的活靶子:
- 文献综述按“A说...B认为...C指出...”机械罗列
- 研究方法照搬教材实验步骤模板
- 讨论部分过度使用“本研究印证了X的结论”
2. 引用技术的“陷阱”
我见过最冤的案例是学生认真标注了出处,但查重系统仍将:
- 连续5个单词与数据库重复即标红
- 间接引用未彻底改写句式
- 引用多个文献形成“拼接式重复”
这里插个救命技巧:论文查重阈值标准差异要看清!Turnitin默认5词连续即算,而知网是13字符。建议写作时用“概念A(X,2010;Y,2015)共同指出...”这类爆破式引用打破连续性。
3. 学科特性的“无奈”
| 学科类型 | 高危区域实例 | 应对策略 |
|---|---|---|
| 医学/生物学 | 疾病定义、标准诊疗路径 | 用流程图替代文字描述 |
| 法学/政治学 | 法律条文、政策原文 | 附录展示+正文深度解读 |
| 工程学 | 设备参数、标准规范 | 用三维模型图示标注 |
三、实战优化:三招拆解重复率困局
▶ 改写核武器:三角转换法
当遇到必须引用的定义时,试试我的压箱底技巧:
原句:“认知失调理论认为个体面对矛盾信息时产生心理不适”(Festinger,1957)
转换后:“Festinger(1957)的经典研究揭示,当人们同时接触两个冲突认知时,会产生类似生理疼痛的心理紧张状态”
三步拆解:①转换主语结构 ②同义词替换关键术语 ③添加具象化比喻
▶ 引用巧布局:信号词阻断术
通过增加“值得注意的是”“特别需要阐明的是”等过渡语,有效切断连续字符匹配。论文引用规范对学术诚信评分影响的数据显示,合理使用过渡词的论文重复率平均降低17%。
▶ 善用技术防护:预查重策略
投稿前务必做两轮自检:
- 初稿用Grammarly检查基础重复
- 定稿用目标期刊同款系统检测(查论文查重阈值标准差异)
某顶刊主编曾私下透露:他们会特别关注论文重复率对期刊接受率的影响阈值附近(如18%-22%)的稿件,此时写作质量才是突围关键。
四、深层启示:超越查重的学术传播
解决重复率只是底线,真正的战场在投稿后:
- 在ResearchGate发布图表解析增强影响力
- 用3分钟视频摘要说明研究创新点
- 将文献综述转为科普文投学术公众号
去年我带的学生把论文方法部分改写成《小白也能懂的实验设计指南》发在知乎,不仅阅读破10万,还被期刊编辑主动约稿。这才是现代研究者的生存之道!
最后的话:理性看待那13%
记住:论文查重阈值标准差异的存在意味着——10%的重复率可能是5个规范引用堆积的结果。与其被数字绑架,不如掌握“解释权”:在投稿信中说明高重复章节的正当性,附上原始文献列表。
更重要的是培养数据驱动的写作意识:用Citavi管理文献时标记“高危引用”,在Scrivener里设置重复词警报。当你理解重复率检测工具原理的运作机制,就能写出既合规又灵动的论文。
毕竟,我们的目标不是成为查重系统的漏网之鱼,而是让原创思想穿透数字的铁幕。
更多关于- 查重报告背后:什么特征的论文更容易触发“重复率警报”? - 请注明出处
发表评论